






The Revolution That Started in the Lab
Over the past decades, we have witnessed a quiet yet powerful transformation in computer vision: synthetic data has shifted from an experimental resource to the backbone of cutting-edge commercial applications. What began as academic research now powers everything from autonomous vehicles to industrial safety systems.
Digital Humans: The Breakthrough That Opened the Way
The Max Planck Institute for Intelligent Systems, led by Michael J. Black, established the paradigm that changed everything. His line of research in digital humans not only solved complex technical challenges but also proved that synthetic data can surpass real data in quality and scale.
Over the years, the group developed resources that shaped the field:
- 2009–2011 – HumanEva / Human3.6M: The first datasets with accurate 3D motion capture, laying the groundwork for pose estimation.
- 2015 – SMPL: The parametric model that revolutionized 3D human body representation. Compact, animatable, and still the backbone for dozens of later datasets.
- 2017 – SURREAL: A true milestone. 6 million synthetic images with perfect annotations for 3D pose, depth, and segmentation. Proved that networks trained only on synthetic data could compete in real-world tasks.
- 2019 – AMASS: A unified repository aggregating mocap datasets, enabling realistic human motions at industrial scale.
- 2020 – CLOTH3D: Realistic physical simulation of clothing in motion, expanding beyond the naked body toward commercial realism.
- 2021 – ReSynth: Physically realistic clothing applied to digital humans, improving generalization in clothing vision.
- 2020 – 2023 – SMPL-X, AGORA, BEDLAM: More realistic models (facial expressions, hands, clothing) and highly complex datasets, covering interactions, varied environments, and challenging conditions.
Measured Impact in Citations
The impact of this research line goes beyond the number of datasets created: it is clearly reflected in scientific metrics.
Michael J. Black’s citation graph on Google Scholar shows consistent growth since 2009, from roughly 500 citations per year to more than 15,000 in 2023.
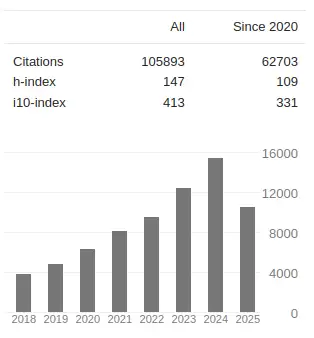
the last 8 years. Source: Google Scholar
This curve demonstrates that synthetic data is not just a passing trend but a consolidated pillar of computer vision research.
Beyond Digital Humans
- Autonomous Driving:
- 2016 – SYNTHIA: A pioneer in synthetic urban scenarios, simulating controlled traffic conditions.
- 2017 – CARLA Ecosystem: Not just a simulator, but a complete platform generating datasets like CarlaScenes, enabling millions of safe driving test scenarios.
- 2018 – Virtual KITTI: Evolution of the famous real KITTI dataset, with 50 variations per sequence — weather, time of day, and camera configurations impossible to capture naturally.
- 2025 – RealDriveSim: The latest leap. 133,780 frames with synchronized camera and LiDAR (32 and 64 beams), covering 6,689 unique road segments. Models trained here outperform previous benchmarks.
- Safety and Monitoring
- 2023 – CrowdSim2: Synthetic videos in Unity simulating pedestrians and vehicles under all weather conditions — sun, rain, fog, snow. Showed how environmental factors impact object detectors in real scenarios.
- 2025 – SynthmanticLiDAR: Semantic segmentation for LiDAR point clouds using CARLA, aligned with SemanticKITTI. Significantly improves algorithm accuracy on real LiDAR data.
- Text Processing
- 2016 – SynthText: Millions of synthetic images with embedded text in natural scenes, revolutionizing OCR and text detection in complex environments.
The Challenge of Specialization
Despite these revolutionary advances, most public datasets remain concentrated in a few domains: people, urban traffic, text. Entire sectors are still uncovered — agriculture with complex seasonal variations, industry with hazardous environments and specialized sensors, healthcare with delicate medical procedures, retail with dynamic product–customer interactions, and energy with critical infrastructure inspections.
This gap represents both a challenge and an opportunity. The techniques are mature, the effectiveness is proven, but adoption remains limited to a handful of well-explored domains.
It is precisely in this gap between consolidated research and unmet industrial needs that the biggest opportunities for innovation lie.
SynthVision: Democratizing the Revolution
At SynthVision, we believe the synthetic data revolution should not remain confined to academic labs or big tech corporations. With the same technology that allowed Max Planck researchers to surpass real data in human estimation, we develop tailor-made datasets for any industry using computer vision.
Our approach combines advanced 3D modeling, precise physical simulation, and full scene parameter control. This allows us to create synthetic environments that not only replicate reality but surpass it in variability and control. Where real capture faces limitations of cost, safety, or logistics, synthetic data offers complete freedom.
The advantage lies not only in development speed — weeks instead of years — but also in the intrinsic quality of the data: annotations perfect by design, fully adjustable parameters, the ability to generate millions of samples when needed, all at a fraction of the cost of real-world equivalents.
The Future That Has Already Begun
The work of the Max Planck Institute established a definitive truth: synthetic data not only competes with real data — in many cases, it surpasses it. Examples like BEDLAM, Virtual KITTI, and SynthText have already proven this in human modeling, urban driving, and OCR.
This robust scientific evidence paves the way for full democratization of the technology. If academia has already demonstrated feasibility in digital humans and autonomous driving, there is no technical reason to confine this revolution to a few domains.
SynthVision represents this natural expansion — bringing the proven power of synthetic data to agriculture, industry, healthcare, energy, and any sector that depends on computer vision.
The future of computer vision is not about capturing reality, but about simulating it with full control. This revolution, once limited to research labs, is now available to any industry — and SynthVision is the gateway.
The synthetic data revolution has left the labs. Now it’s time to apply it to your industry.