
SynthVision Consulting
Building Better AI With Synthetic Data
We generate high-quality, photorealistic synthetic datasets for computer vision — with pixel-perfect annotations, fast delivery, and full scene control.

No Real Data
Needed
No photos, no privacy risks — all scenes are built from visual references, not real-world data.
100% Accurate Annotations
Every pixel labeled — no bias, no noise, no human mistakes. Just clean, consistent annotations.
Real Results,
Fast
From kickoff to dataset in 1–2 weeks — with fast cycles to refine and reach your model goals.
Design for Learning
We guide your model — simplifying scenes to reduce noise and focus attention where it matters.
How It Works
From Problem to Dataset in Days
We transform your vision into high-quality synthetic datasets through a fast, structured, and flexible process — ready to support your AI models from day one.
- Understand your use case and goals
- Build 3D scenes tailored to your environment
- Generate thousands of annotated images in days
- Validate performance and iterate when needed
📌 No need to collect, clean or label real-world data.
Who We Work With
Trusted Across Industries



Use Case Highlights
What We Can Simulate
Aerial Imagery with Realistic Light & Terrain Control
We create high-quality aerial images with precise lighting and terrain variations. Unlike standard augmentations, our synthetic data ensures realistic, adaptable environments for AI training.

Customizable Objects & Scene Modifications
Our synthetic data goes beyond simple recoloring. We modify objects, swap equipment, and change environments while preserving pixel-perfect annotations for high-performance AI models.

Scalable Scene Adjustments for Maximum Variability
We generate diverse datasets by adjusting lighting, product arrangements, and object presence. This controlled variability enhances AI training for real-world applications.
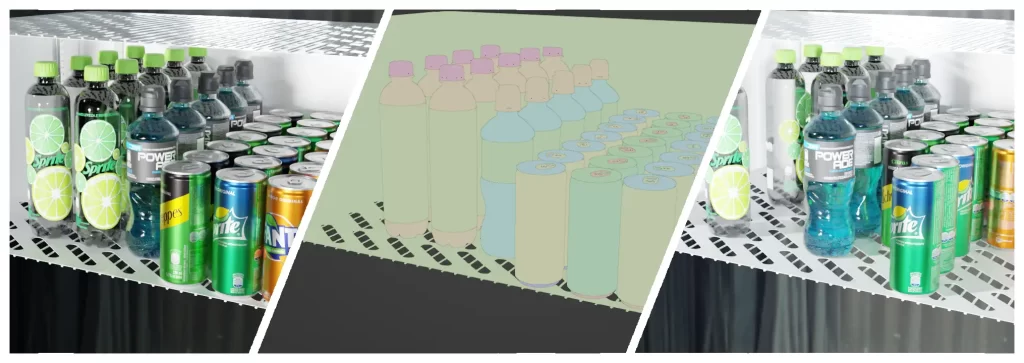
Hyper-Realistic Lighting & Multi-Scale Data
From close-up details to aerial perspectives, we simulate complex lighting and individual object shadows. Our datasets provide the precision needed for high-resolution AI models.

Damage Simulation with Precise Object Control
We create realistic damage scenarios with full customization—altering car colors, crash patterns, and backgrounds. This enables AI models to detect and analyze defects with exceptional accuracy.

Who We Are
Meet the Founder

Guilherme Bileki
Founder & Computer Vision Specialist
With deep expertise in AI and simulation, Guilherme created SynthVision to help companies solve real-world problems — without real-world data. His focus is on scalability, precision, and performance.
FAQ
Frequently Asked Questions
What exactly are synthetic data and why should you use them?
Synthetic data are artificially generated images or data that mimic real-world situations. At SynthVision, they are created entirely from scratch using 3D scenes — no real photos or user data involved. This allows teams to train AI/ML models while overcoming issues of privacy, bias, cost, and data scarcity.
What are the benefits of using synthetic data for model training?
Synthetic data allow for unlimited variation in controlled environments. This improves model generalization, expands training coverage (including edge cases), and accelerates development. Since annotations are generated automatically, they’re pixel-perfect and free of human error. It also eliminates privacy concerns entirely.
What is the difference between simulated synthetic data generation and generative AI?
Simulated synthetic data generation creates data through 3D environments and physical simulations, reproducing real conditions of lighting, physics, and textures. Generative AI, such as Generative Adversarial Networks (GANs), creates new data by learning patterns from existing datasets. Simulated generation is more controlled and precise, while generative AI offers greater flexibility in data creation but with less control over environmental details. At SynthVision, we use fully simulated 3D scenes for maximum control, physical accuracy, and annotation quality.
Is it possible to seamlessly integrate real data with synthetic data?
Yes — when real data is available, we use it exclusively for validation and fine-tuning. Synthetic data is used for training, ensuring scalability and coverage. If real data is not annotated, we offer optional support to label it using the trained model and a human review step.
How do you ensure synthetic data covers edge cases and out-of-distribution (OOD) scenarios?
Our 3D scenes allow controlled variation of lighting, camera angles, materials, and object behaviors — generating edge cases and rare events on demand. Even without real data, the scale and diversity of synthetic variation help cover outliers and reduce the model’s domain gap.
How can I get started using SynthVision’s services effectively?
Just contact us and share your use case. We’ll assess your needs and recommend the best approach — from proof of concept to full dataset generation. We work flexibly with both startups and large-scale teams.

Ready to accelerate your AI with synthetic data?
From proof of concept to full deployment — let’s make your model smarter, faster, and safer.
From Our Blog Posts
All the Latest SynthVision Stories
-

SynBalance: balancing rare classes with synthetic data
Computer vision models tend to learn more about what they see often — and much less about what they see rarely.This is the classic challenge of long-tailed distributions: some classes (like “cat” or “car”) have thousands of examples, while others (“anteater”, “tractor”) appear only a few times. The paper SynBalance: Harnessing Synthetic Data in Long-tailed…
-

Synthetic Data in Computer Vision: From Scientific Revolution to Industrial Applications
The Revolution That Started in the Lab Over the past decades, we have witnessed a quiet yet powerful transformation in computer vision: synthetic data has shifted from an experimental resource to the backbone of cutting-edge commercial applications. What began as academic research now powers everything from autonomous vehicles to industrial safety systems. Digital Humans: The…
-

ROSE: Object Removal in Videos Powered by Synthetic 3D Data
Generative models have made impressive progress in video editing and manipulation, but there’s still one very hard challenge: completely removing objects — not only the object itself, but also the side effects it creates such as shadows, reflections, illumination changes, translucency, and even mirror appearances. The recent work ROSE (Remove Objects with Side Effects in…
-

DAViD by Microsoft: A Public Milestone in Computer Vision with Synthetic Data
When it comes to computer vision and synthetic data, we often see closed-off research — applied to proprietary contexts and far from public access. That’s why the recent DAViD project (Data-efficient and Accurate Vision models from synthetic Data), presented by Microsoft at ICCV 2025, stands out: it was fully released to the public, including code,…