






Computer vision models tend to learn more about what they see often — and much less about what they see rarely.
This is the classic challenge of long-tailed distributions: some classes (like “cat” or “car”) have thousands of examples, while others (“anteater”, “tractor”) appear only a few times.
The paper SynBalance: Harnessing Synthetic Data in Long-tailed Recognition, presented at ICCV 2025, proposes an elegant way to tackle this imbalance: using synthetic data generated by generative AI to balance class frequencies and teach models to recognize rare cases more effectively.
What is SynBalance?
SynBalance is a pipeline that combines real and synthetic data to improve performance on unbalanced datasets.
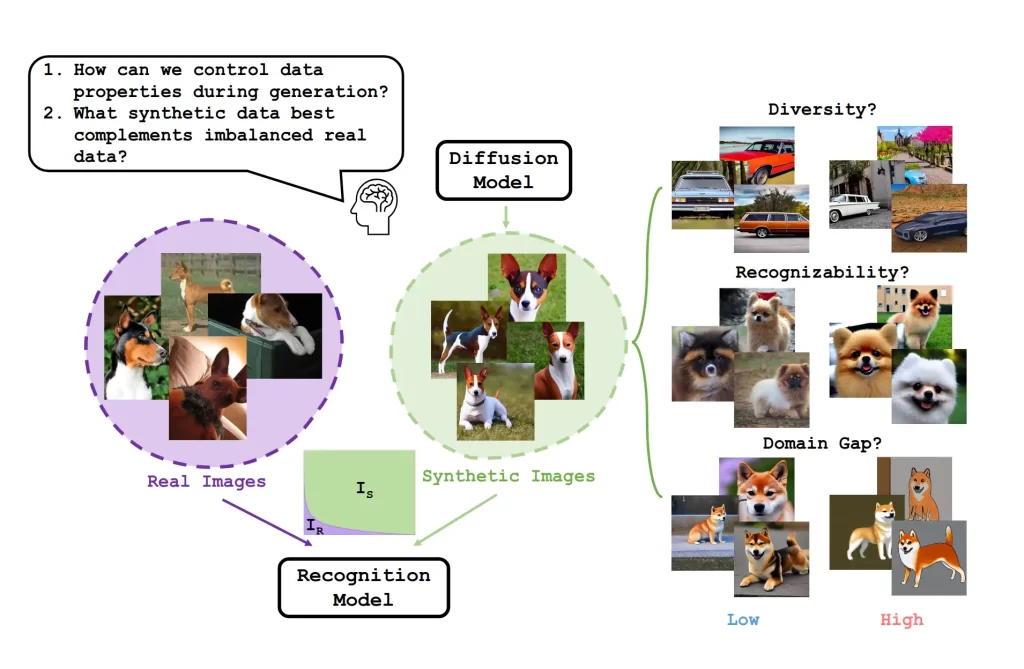
The idea is simple but powerful: generate additional images only for the classes that lack examples — and do it intelligently, by adjusting not just the amount but also the diversity and clarity of the generated images.
To achieve this, the authors used diffusion models such as Stable Diffusion v1.5 to create new images from textual descriptions (“a photo of a tiger,” “a cargo plane in the sky,” etc.).
These synthetic samples are then analyzed and selected based on four main criteria:
- Diversity – how different the images are from each other.
- Recognizability – how easily a model can understand what it sees.
- Domain gap – the visual difference between real and synthetic samples.
- Quantity – how many new samples each class actually needs.
This adaptive selection process results in a “balanced” dataset that effectively mixes real and synthetic images.
What the study showed
In their experiments, SynBalance achieved significant gains in recognizing rare classes.
On benchmarks such as ImageNet-LT and iNaturalist, the method outperformed several baselines, demonstrating that synthetic data truly helps models pay attention to what they used to overlook.
In short: by adding carefully selected synthetic data, SynBalance improved overall accuracy — and especially boosted performance in the long-tail classes that models typically struggle with.
But there’s an important catch
The authors also acknowledge a key limitation: their synthetic images were generated with Stable Diffusion v1.5, a general-purpose generative model designed for art and illustration — not for scientific or machine learning datasets.
This means that while SynBalance delivered measurable improvements, the image quality and realism were still limited.
Some generated samples lacked visual fidelity, which reduced the potential benefits. Moreover, generative AI pipelines tend to be computationally expensive and unpredictable — you can’t fully control what each image will look like.
In other words: the concept is excellent, but the data generation method still has room to improve.
How controlled synthetic data can go further
Now imagine if, instead of using a generic GenAI, the authors had generated their data in fully controlled 3D environments, with complete control over lighting, materials, angles, and object classes.
That would enable:
- Perfectly realistic and consistent images, free from visual artifacts.
- Precisely balanced classes, with exact control over how many examples each one gets.
- Automatic and detailed annotations, including masks, bounding boxes, instance labels, depth maps, and even hyperspectral information.
That’s exactly the kind of control offered by SynthVision’s synthetic data pipelines — and it’s what could take the SynBalance idea far beyond what the paper demonstrated.
While SynBalance focuses solely on image classification, SynthVision’s datasets are built for a wide range of computer vision tasks — including object detection, instance and semantic segmentation, visual odometry, and hyperspectral imaging — all with precise, consistent annotations ready for immediate use in real-world pipelines.
With physically accurate and configurable synthetic data, it becomes possible to achieve even stronger results, reducing the domain gap and accelerating progress in long-tailed recognition and other complex vision tasks.
What SynBalance teaches us
The study delivers a clear message: synthetic data works — and when used purposefully, it’s a powerful tool to overcome the limitations of real-world datasets.
The next step is to move from “AI-generated” to “design-controlled” data — using physically realistic 3D simulations and parameterized variations to produce scientifically reliable datasets.
This is where machine learning and 3D synthesis truly converge — and where the next breakthroughs in visual intelligence will happen.
Want to explore this approach in your next project?
At SynthVision, we create custom 3D synthetic datasets — with photorealistic rendering, precise annotations, and full control over every variable in the scene.
Perfect for problems where real data is scarce, unbalanced, or costly to collect.
Contact SynthVision to discover how controlled synthetic data can accelerate your vision models.